И даже у меня теперь есть достижение.. После новогоднего безумия, о котором я впрочем умолчу ) и после двух дней за сериалами, я решился попрограмить для профилактики отупения да подключения мозгов к реальности путём алгоритмизации их действий, чего не делал путью более полугода.. Ну и с ходу врубился в ассинхронное программирование на Python, чем даже близко не мог похвастаться в годах минувших.. Вот и пришлось начать таки писать бота по сбору и анализу криптовалютных биржевых котировок через websockets.. Ну и вообще это был решающий момент в моей карьере программиста реальности, от которой я уж было думал отказаться в пользу более приземлённого дизайнера реальности с элементами маркетолога реальности. Но одно с другим третьему не мешает и всё приходит вовремя. Спасибо за внимание )
Метка: код
Высшее IT

…
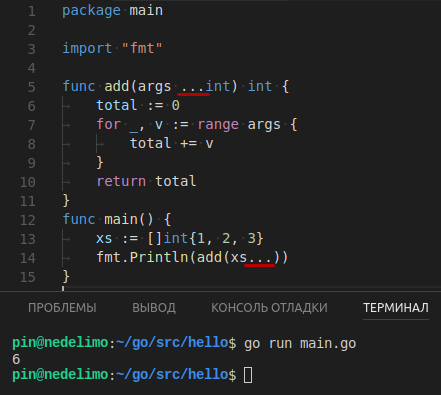
Если кто-то думает, что это только я так угораю… то это довольно далеко от истины …подобную конструкцию в языке Go можно встретить столь же запросто, сколь и в этом блоге. Она обозначает, что сущность склонна принимать/передавать любое количество аргументов. Подобно моим мыслям, которые крайне редко бывают высказаны до конца, а стартуют, как правило, ни разу не с начала.
Нейро-медитация
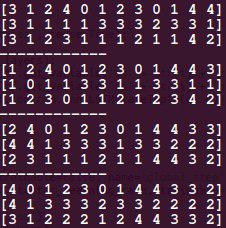
После месяца всепоглощающего и глубочайшего погружения в TensorFlow, я вот думаю пока на этом пристопиться и подумать, чего же я всё-таки натворил… В Нейронную Сеть поступают X и Y. X — цены разбитые на равные интервалы между началом и концом которых взята разница. Разницы сглажены L2-Norm в окнах по некому количеству этих интервалов и округлены до сотых. То есть в окне мы имеем N интервалов, выраженных числом от -1 до 1. Y ещё веселей. Во первых он на 1 интервал опережает X. Он так же сглажен в таких же окнах. Но вот интервал выражен целым числом количества состояний от 0 до 4, где 0 максимальное падение, а 4 максимальный рост, в рамках окна но с прицелом на весь набор данных, чтобы 0, 1, 2, 3 и 4 было примерно поровну на весь массив.
По итогу:
Y — Первый ряд — ну как бы контрольное значение, к которому надобно стремиться.
X поступает в Рекуррентную сеть (Recurrent) с двумя LSTM (долгая краткосрочная память) ячейками по 512 юнитов памяти на каждую, её вывод проходит через слой нейронов той же размерности, на выходе выдавая Ересь#1 из которой я делаю Второй ряд, выбирая максимальные значения из предложенных вариантов, количество которых равно числу состояний.
И на этом можно было бы остановиться, но я запускаю изначальную Ересь#1 от Рекуррентной в Свёрточную сеть (Convolutional), где она проходит чрез две конволюции, два пула и два слоя нейронов, подгоняясь, разумеется, к Y; и уже из получившейся Ереси#2 делаю Третий ряд, округляя её до целых.
Видно, что они стараются, но не хватает мощности это всё обсчитать… Ибо нужно поднавалить нейронов и дать массив раз в 10 побольше. Желательно увеличить окно хотя бы до 20… Круто бы хотя бы 7 состояний вместо 5… В общем, увеличить все параметры… На каком-то этапе явно придётся арендовать GPU ибо вроде как Туда… Ведь вы уже поняли, что последний столбик — это 1 интервал в Будущее?
вПереносном
А вот бы было классно замутить на своём сайте переносы, как в книжках прямо… Вроде поначалу непривычно для Web, но если приглядеться, то всё быстро становится на свои места. Было бы желание, а решение в современном мире найдётся, это не двухтысячные с IE6.
На старте объявляем браузеру, что текст на русском, если на другом, то ясно, что делать. Теперь он будет использовать свою базу всяческих языковых примочек, включая правила переноса.
<html lang="ru">
Далее, разумеется, CSS, где всё также весьма прозаично и на самом деле довольно вольно.
article {max-width:999px}
article p {
text-align: justufy;
hyphens: auto;
/* ну и на всякий случай */
overflow-wrap: break-word;
-moz-hyphens: auto;
-webkit-hyphens: auto;
-ms-hyphens: auto
}
Вауля!